Introduction
Large Language models (LLMs) are AI model which is generated to understand, process and generate the human languages. LLMs are train on the vast amount of data which helps LLMs to understand and recognize the pattern during training. The main goal of LLMs are to predict the Next Token, In simple word the primary goal of LLMs are to predict which word should next according to there probability.
Example:-
Prompt: The capital of India is Model will predict the next word according to the probability.
model response: The capital of India is Delhi. and continuously predict the word till it reaches to end.
Some Examples of LLMs are:
- GPT models
- Llama
- Gemini
GPT : Generative Pre-trained Transformer.
Evolution of LLM:
In Evolution process we were initially working on LSTM-based models (Long Short Term Memory models) or we can say with seq2seq models which were created to solve Asynchronous many-to-many model problems. Which are used in field of NLP like:
- Machine translation
- Text Summarization
- Question Answer Model
- Chatbots
- Speech-to-text model
It is used to solve the difficult NLP problems.
The flow of Evolution is:
Encoder Decoder architecture → Attention mechanism → Transformers → Large Language models1. Encoder Decoder Architecture:
In 2014, There was a team of researchers in google including “Ilya Sutskever, Oriol Vinyals and Quoc Le ” (Later Ilya sutskever become one of the co-founder of OpenAI) they published a paper on Sequence to Sequence Learning (seq2seq) learning named “Sequence to Sequence Learning with Neural Networks”. In this we predict the Output sequence according to Input sequence. They use LSTM (Long Short Term Memory) concept this is a kind of RNN network which is used in machine learning to process the sequence data.
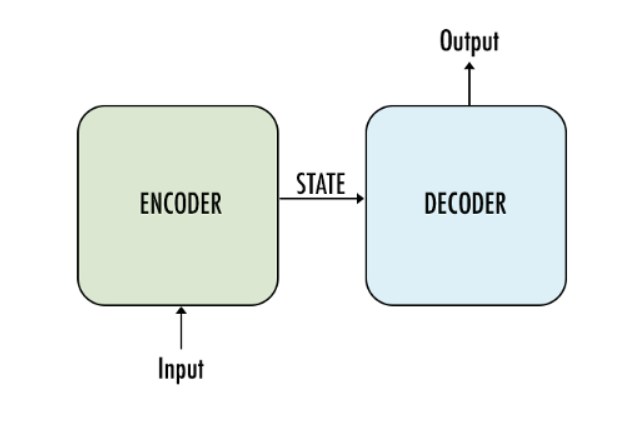
Here Encoder and Decoder is consist of RNN Layers and when the user enters any prompt, then the prompt is taken as input by Encoder and the prompt is tokenized into token and processed in sequence and Encoder compress the user prompt and then further send it to state element which stores the whole compressed data, here the whole process is being in sequence, now the compressed data is received by the Decoder which Transform the data, During training Decoder is trained on supervised Input and output patterns. These model was best for short sentences.
Now in this model there were some limitations which are:
- The sentence is processed word by word
- Small Context size
- Only 30 words can processed at a time. Model only remembers the last 30 input characters.
2. Attention Mechanism:
In 2015, “Bahdanau, Cho and Yoshua Bengio” famous Authors publish a research paper “Neural Machine Translation by Jointly Learning to Align and Translate” In which they explained the concept of attention mechanism and how they are solving the problem of Encoder decoder model. He explained in this paper that the potential issue in encoder decoder was that the neural network compress the necessary information of the source sentence into a fix length vector. It create problem nor neural network to cope with long sentences in training corpus.
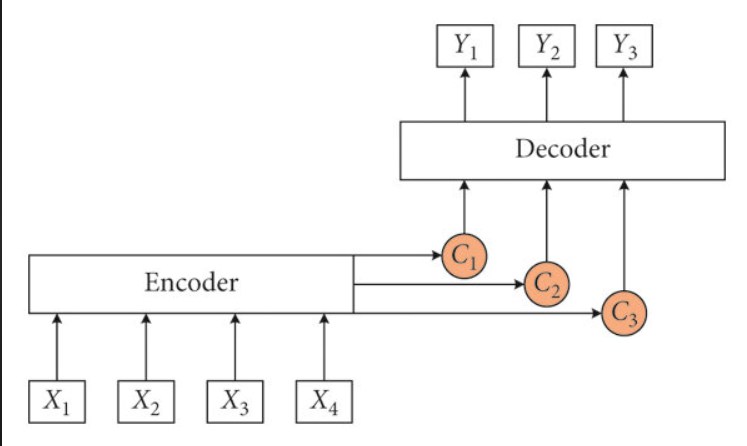
In Attention mechanism model Yoshua bengio introduce an attention layer in Decoder, here the encoder works same as it was working in encoder decoder model but here the context size is different according to the size of Input. In attention mechanism the Decoder have the whole tokenized user prompt in each step which help them to understanding the prompt better and generate better response according to it. Here attention layer works to predict the context of the words.
limitations of Attention mechanism:
- High computational Complexity
- Repetitive calculation of similarity score
- Quadratic time complexity
3. Transformers:
In 2017, A paper is published by Google named “Attention is all you need” This paper introduced the Transformer Architecture, which became the foundation of modern Natural Language Processing (NLP) and Large Language Models (LLMs). Here for the first time Transformer architecture is used. Here google removed the concept of LSTM (Long Short Term Memory) and RNN cell. Transformer provided the feature of parallel processing.
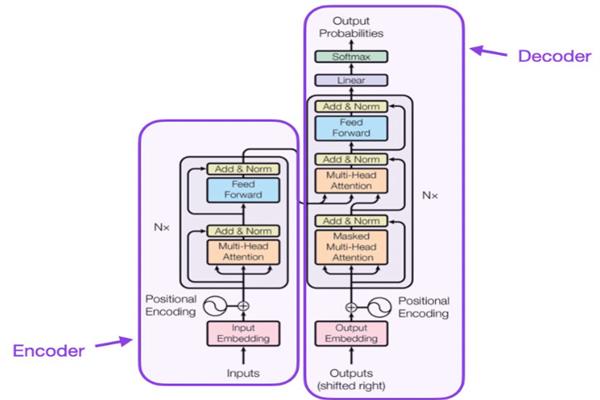
These model were work in process like self-attention (This provides the capability to communicate with the other word in same sentence and find there position and context) and Parallel processing. It resolves the problems in above models and bring a new concept.
Limitations of Transformers:
- Complex to understand
- Required high performance GPU
- Time to train in high
- It needs a very high amount of data to train the model
4. LLMs:
In 2018, Google introduced “BERT” and OpenAI introduced “GPT” (Generative Pre-trained Transformer) models which is the starting of LLMs era. BERT is an Encoder only model and GPT is Decoder only model. LLMs enables to download the transformers and can fine tune according to use. LLMs have the Quality like:
- Data → it needs billions of data to train the LLMs.
- Hardware → Cluster of GPUs are required.
- Training time → training time is very high it takes days to weeks to train a model.
- Cost → It includes high cost of Hardware, electricity, infrastructures and export charges.
- Power consumptions → It requires power to train approx in which a small city can use the power for a month .
How to Create an LLM (Large Language Model): Step-by-Step Guide