0
What is regularization, and why is it used in machine learning?
2 Answers
0
Overview:
Regularization is a technique used in machine learning to prevent overfitting and work on the speculation of prescient styles. Overfitting happens while a rendition figures out how to hold onto clamor or irregular vacillations inside the preparation records, fundamental to terrible by and large execution on concealed records. Regularization permits moderate this trouble through adding a punishment term to the model's objective trademark, beating complex down or excessively bendy molds that are in danger of overfitting.
The main motivation behind regularization is to strike a strength among limiting the preparation botches and controlling the intricacy of the rendition. By punishing immense boundary values or rendition intricacy, regularization empowers less troublesome styles, which are less likely to overfit. Regularization methodologies normally contain adding a regularization term to the misfortune capability, however long schooling might last.
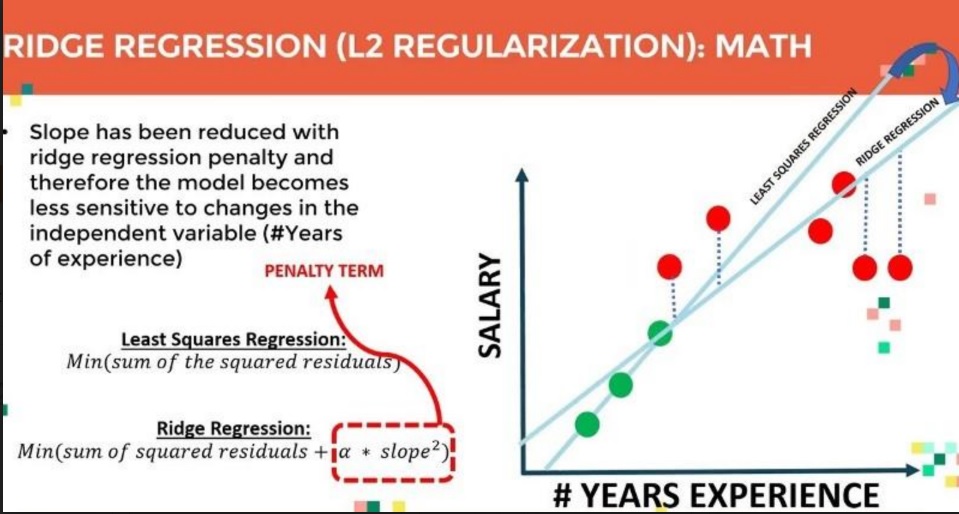
One typical state of regularization is L1 regularization, moreover alluded to as rope regularization, which gives totally the upsides of the rendition coefficients as a punishment term. This supports sparsity in the model, accurately contracting a couple of coefficients to nothing and choosing the most extreme essential capacities. Another popular strategy is L2 regularization, likewise called edge regularization, which adds the squared sizes of the coefficients as a punishment time span. L2 regularization punishes gigantic boundary esteems extra gently than L1 regularization and is frequently more prominent and strong while there are associated capacities inside the data.
Regularization is fundamental in framework dominating on the grounds that it empowers keep styles from retaining commotion in the tutoring records and makes them more noteworthy solid to varieties in concealed realities. By selling less troublesome designs with fewer boundaries or more modest boundary values, regularization supports models that hold onto the fundamental styles in the data without overfitting to commotion. This results in more prominent exact expectations and higher execution by and large while sent in genuine world bundles.
Read more: What is regularization, and why is it used in machine learning
1
In machine learning, regularization is a technique used to prevent overfitting and improve the generalization of a model. Overfitting occurs when a model learns the noise and details in the training data to the extent that it performs poorly on new, unseen data.
Regularization introduces a penalty term to the model's loss function, discouraging the model from learning overly complex patterns that may not generalize well. This penalty is typically based on the magnitude of the model's coefficients, aiming to keep them small.
Regularization is used to strike a balance between fitting the training data closely and maintaining simplicity and generalization, ultimately leading to better performance on unseen data.