In Machine Learning, many beginners believe that choosing the best algorithm automatically leads to the best results. However, experienced data scientists know that the quality of features often matters more than the choice of algorithm.
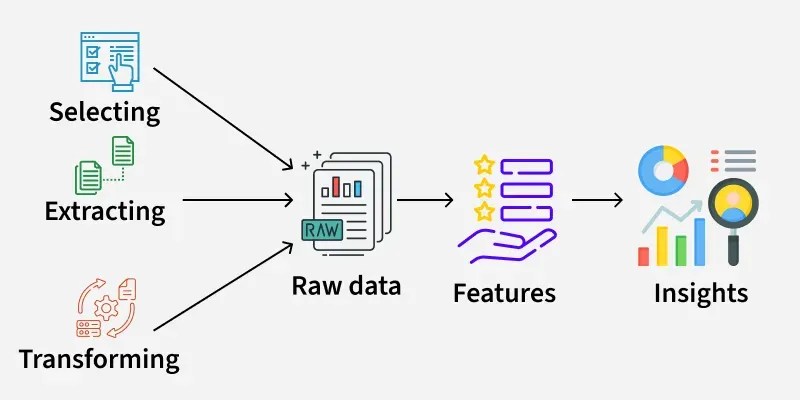
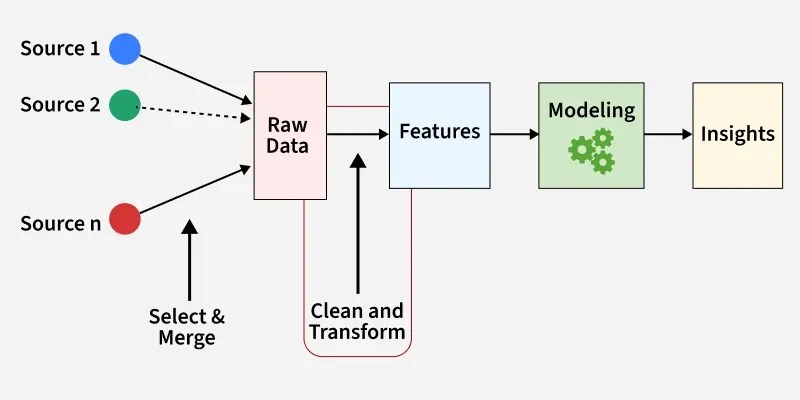
This process of transforming raw data into meaningful inputs for a model is called Feature Engineering. It is one of the most critical steps in Data Science and often determines whether a model succeeds or fails.
What is Feature Engineering?
Feature Engineering is the process of creating, transforming, or selecting variables (features) from raw data to improve the performance of machine learning models.
A feature is simply an input variable used by a model to make predictions.
Example dataset for predicting house prices:
| Feature | Description |
|---|---|
| Area | Size of the house |
| Bedrooms | Number of bedrooms |
| Location | City or neighborhood |
| Age | Age of the property |
A machine learning model uses these features to predict the house price.
However, raw data is rarely perfect. Feature engineering helps transform it into something more useful.
Why Feature Engineering is Important
Even the most advanced algorithms cannot perform well if the input data is poorly structured.
Good feature engineering helps:
- Improve model accuracy
- Reduce noise in data
- Capture hidden patterns
- Make models easier to train
Many winning solutions in data competitions rely heavily on strong feature engineering rather than complex models.
Common Feature Engineering Techniques
1. Handling Missing Data
Real-world datasets often contain missing values.
Example:
| Age | Income |
|---|---|
| 30 | 50000 |
| NA | 45000 |
| 28 | NA |
Common approaches include:
- Replacing missing values with mean or median
- Using the most frequent value
- Predicting missing values using other features
Handling missing values properly prevents models from learning incorrect patterns.
2. Encoding Categorical Variables
Machine learning models usually require numeric data, but many datasets contain text categories.
Example:
| City |
|---|
| Delhi |
| Mumbai |
| Delhi |
We convert these into numbers using techniques such as:
Label Encoding
Delhi = 1
Mumbai = 2
Chennai = 3
One-Hot Encoding
Delhi Mumbai Chennai
1 0 0
0 1 0
1 0 0
These methods allow algorithms to process categorical information effectively.
3. Feature Scaling
Different features may have different ranges.
Example:
| Feature | Range |
|---|---|
| Age | 20–60 |
| Salary | 20,000–200,000 |
Large values may dominate smaller ones, affecting some algorithms.
Common scaling methods include:
- Normalization
- Standardization
Scaling is especially important for algorithms such as Support Vector Machine and K-Nearest Neighbors.
4. Creating New Features
Sometimes combining existing features reveals useful patterns.
Example:
Raw features:
Date of BirthEngineered feature:
Age = Current Year – Birth YearAnother example:
TotalPurchase = ItemPrice × QuantityThese derived features often improve model performance.
5. Feature Selection
Not every feature is useful. Some may even harm model performance.
Feature selection helps identify the most important variables.
Techniques include:
- Correlation analysis
- Recursive Feature Elimination
- Feature importance from models such as Random Forest
Removing unnecessary features can reduce model complexity and training time.
Example of Feature Engineering in Practice
Suppose we want to predict whether a customer will purchase a product.
Raw dataset:
| Age | City | Last Purchase Date |
|---|
After feature engineering:
| Age | City_Delhi | City_Mumbai | Days_Since_Last_Purchase |
|---|
These engineered features allow the model to detect patterns more effectively.
Feature Engineering vs Feature Selection
Many people confuse these two concepts.
Feature Engineering
- Creating or transforming new features.
Feature Selection
- Choosing the most useful features from the dataset.
Both processes are essential for building effective models.
Real-World Applications
Feature engineering is used across many industries:
- Finance
- Fraud detection
- Credit scoring
- Healthcare
- Disease prediction
- Risk assessment
- E-commerce
- Customer recommendation systems
- Purchase prediction
- Marketing
- Customer segmentation
- Campaign optimization
Challenges in Feature Engineering
Despite its importance, feature engineering can be difficult because:
- It requires domain knowledge
- It can be time-consuming
- Poor transformations may introduce bias
This is why feature engineering is often considered more of an art than a science.
Conclusion
Feature engineering is a critical step in building successful machine learning systems. By transforming raw data into meaningful inputs, data scientists enable algorithms to capture patterns and produce accurate predictions.
While modern models and automated tools are improving, thoughtful feature engineering remains one of the most powerful ways to improve model performance in Artificial Intelligence systems.
In many cases, better features outperform more complex algorithms, making feature engineering a skill every data scientist should master.