A Decision Tree is one of the most intuitive and easy-to-understand algorithms used in Machine Learning and Artificial Intelligence. It mimics the way humans make decisions by asking a series of questions and following branches until a final conclusion is reached.
Think of it like a flowchart where each step asks a question, and depending on the answer, you move down a different path. This process continues until the model arrives at a final prediction or classification.
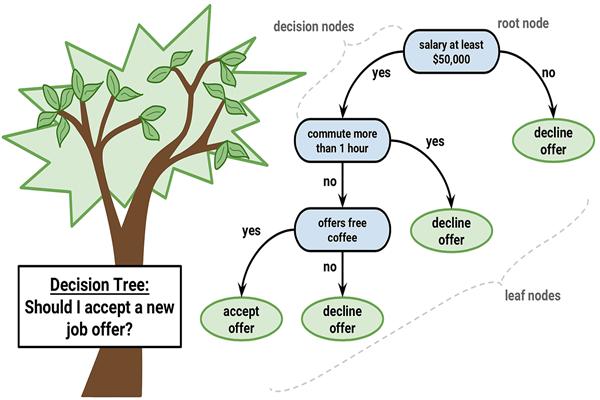
Basic Idea of a Decision Tree
A decision tree works by splitting data into smaller groups based on certain conditions. Each split is designed to make the data more organized so the algorithm can make better predictions.
The tree has three main components:
1. Root Node
The root node is the starting point of the tree. It represents the entire dataset and asks the first important question.
Example:
Is Age > 30?
This question divides the data into two branches.
2. Decision Nodes
Decision nodes are intermediate points where the algorithm asks additional questions.
Example:
Age > 30?
|
|--- Yes → Income > 50K?
| |
| |--- Yes → Buy Product
| |--- No → Not Buy
|
|--- No → Student?
|
|--- Yes → Buy Product
|--- No → Not Buy
Each question helps the model narrow down the possible outcome.
3. Leaf Nodes
Leaf nodes represent the final decision or prediction.
For example:
- Buy Product
- Not Buy Product
These are the outcomes produced by the model.
How the Algorithm Chooses Questions
The key challenge for a decision tree is deciding which question to ask first.
To determine the best split, the algorithm uses mathematical measures such as:
1. Information Gain
Information gain measures how much uncertainty is reduced after a split.
It uses a concept called Entropy, which measures randomness in the data.
- High entropy → Data is very mixed
- Low entropy → Data is more organized
The decision tree chooses the split that reduces entropy the most.
2. Gini Impurity
Another common metric is Gini Impurity, which measures how often a randomly chosen element would be incorrectly classified.
Lower Gini impurity means the split produces purer groups.
Step-by-Step Example
Imagine we want to predict whether someone will buy a laptop.
Dataset features:
- Age
- Income
- Student
- Credit Score
Step 1: Start with all data at the root node.
Step 2: The algorithm tests different splits such as:
- Age
- Income
- Student status
Step 3: It calculates entropy or Gini impurity for each split.
Step 4: The split with the highest information gain becomes the first question.
Example tree:
Is Student?
|
|--- Yes → Buy Laptop
|
|--- No → Income > 60K?
|
|--- Yes → Buy Laptop
|--- No → Not Buy
Types of Decision Trees
Decision trees are used for two main tasks:
Classification Trees
Used when the output is a category.
Examples:
- Spam or Not Spam
- Disease or No Disease
Regression Trees
Used when the output is a numeric value.
Examples:
- House price prediction
- Sales forecasting
Advantages of Decision Trees
- Easy to understand and visualize
- Works with both numerical and categorical data
- Requires little data preprocessing
- Mimics human decision-making logic
Because of these advantages, decision trees are widely used in Data Science applications.
Limitations of Decision Trees
Despite their simplicity, decision trees also have some weaknesses:
- Overfitting – The model may memorize training data instead of generalizing.
- High variance – Small changes in data can produce a very different tree.
- Bias toward features with more levels.
To solve these issues, advanced ensemble methods are used, such as Random Forest and Gradient Boosting.
Real-World Applications
Decision trees are used in many industries:
- Healthcare
- Disease diagnosis
- Risk prediction
- Finance
- Credit scoring
- Fraud detection
- Marketing
- Customer segmentation
- Purchase prediction
- Technology
- Spam detection
- Recommendation systems
Conclusion
A decision tree is a powerful yet simple machine learning algorithm that makes predictions by asking a sequence of logical questions. By splitting data into smaller and more organized groups using measures like entropy and Gini impurity, the model gradually arrives at a final decision.
Because of its interpretability and ease of use, the decision tree remains one of the most important foundational algorithms in modern artificial intelligence systems.