As applications grow, databases often become the first major bottleneck. More users, more data, more reads and writes—eventually a single database server struggles to keep up. Vertical scaling (adding more CPU, RAM, or storage) has limits and quickly becomes expensive.
This is where database sharding comes in.
Database sharding is one of the most powerful techniques for building highly scalable, high-performance systems. In this article, we’ll break down what database sharding is, how it works, its types, benefits, challenges, and when you should (or should not) use it.
What Is Database Sharding?
Database sharding is a form of horizontal partitioning where a large database is split into smaller, independent pieces called
shards.
Each shard contains a subset of the data and runs on its own database server.
Instead of storing all data in one place, sharding distributes data across multiple machines.
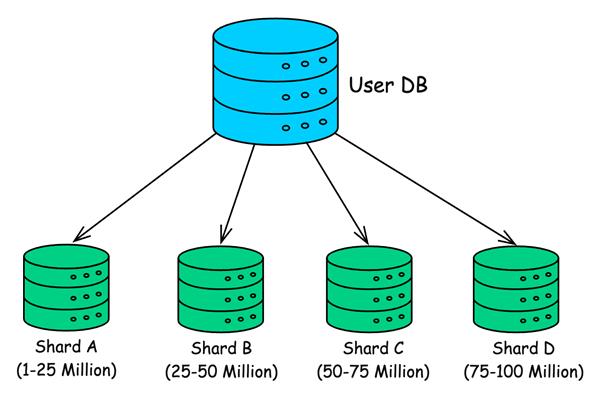
Example:
- Users 1–1,000,000 → Shard A
- Users 1,000,001–2,000,000 → Shard B
- Users 2,000,001–3,000,000 → Shard C
Each shard handles its own reads and writes, dramatically improving scalability.
Why Do We Need Sharding?
- Traditional databases usually scale vertically, meaning:
- Add more CPU
- Add more RAM
- Add faster disks
- But vertical scaling has limits:
- Hardware upgrades are expensive
- Downtime during upgrades
- Physical limits on machines
- Sharding enables horizontal scaling, which allows you to:
- Add more servers instead of bigger servers
- Distribute load evenly
- Scale almost indefinitely
How Database Sharding Works
At a high level, sharding works in three steps:
- Choose a shard key
A shard key determines how data is distributed (e.g.,UserId,CustomerId). - Route queries to the correct shard
The application or a middleware layer decides which shard should handle a request. - Execute operations independently
Each shard processes queries on its own dataset.
From the user’s perspective, the system behaves like a single database—even though data is spread across many servers.
Common Sharding Strategies
1. Range-Based Sharding
Data is split based on a range of values.
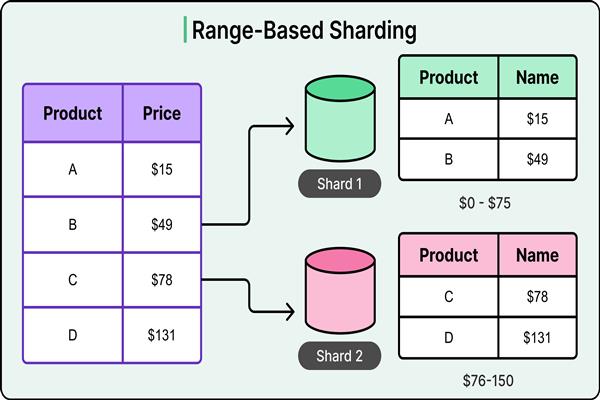
Example:
- UserId 1–1M → Shard 1
- UserId 1M–2M → Shard 2
Pros
- Simple to understand
- Easy range queries
Cons
- Uneven data distribution
- Hot shards if most traffic hits a single range
2. Hash-Based Sharding
A hash function is applied to the shard key.
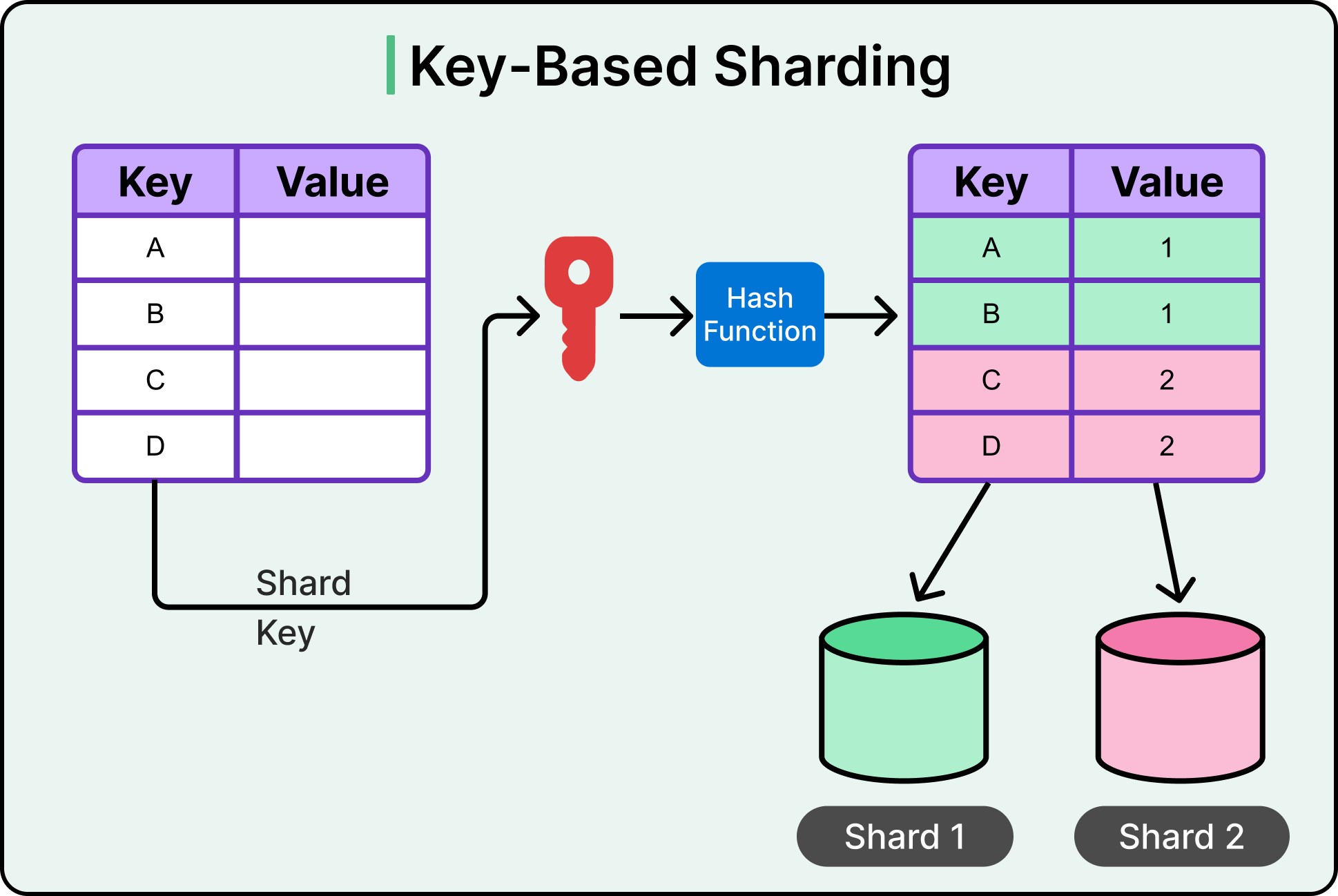
Example:
Shard = hash(UserId) % NumberOfShardsPros
- Even data distribution
- Reduces hot shards
Cons
- Difficult range queries
- Re-sharding is complex when adding shards
3. Directory-Based Sharding
A lookup table maps keys to shards.
Example:
UserId → ShardIdPros
- Flexible
- Easy to move data between shards
Cons
- Additional lookup overhead
- Directory becomes a dependency
Sharding vs Replication
Sharding and replication solve different problems.
| Feature | Sharding | Replication |
|---|---|---|
| Purpose | Scalability | Availability |
| Data | Split across nodes | Copied across nodes |
| Write scaling | Yes | Limited |
| Read scaling | Yes | Yes |
In real systems, sharding and replication are often used together.
Benefits of Database Sharding
- Massive scalability
- Improved performance
- Reduced query load per server
- Better fault isolation
- Cost-effective growth
When done right, sharding allows systems to handle millions—or even billions—of records efficiently.
Challenges and Risks of Sharding
Sharding is powerful, but it is not free.
Increased Complexity
- Query routing logic
- Data consistency across shards
- Distributed transactions
Re-Sharding Difficulties
- Adding or removing shards is complex
- Data migration can be risky
Cross-Shard Queries
- Joins across shards are expensive
- Aggregations become harder
Operational Overhead
- Monitoring multiple databases
- Backup and recovery complexity
- Because of these challenges, sharding should be a carefully planned architectural decision, not a quick fix.
When Should You Use Database Sharding?
You should consider sharding when:
- Your database cannot scale vertically anymore
- Read and write traffic is extremely high
- Data size is growing beyond a single server’s limits
- Performance issues persist despite indexing and optimization
Avoid sharding if:
- Your dataset is small
- Your application is still evolving
- Simpler scaling options are available
Popular Databases That Support Sharding
- MongoDB – Built-in sharding support
- Apache Cassandra – Sharding by design
- MySQL / PostgreSQL – Application-level sharding
- Azure Cosmos DB – Automatic partitioning
- Amazon DynamoDB – Managed sharding
Each database handles sharding differently, so design choices matter.
Conclusion
Database sharding is a cornerstone of modern, large-scale systems. It enables applications to grow beyond the limits of a single database server by distributing data across multiple machines.
However, sharding introduces complexity and should be implemented only when the scale truly demands it. With careful planning, the right shard key, and proper tooling, sharding can turn a struggling system into a highly scalable and resilient platform.