0
What is the difference between Clustered and Non-Clustered index?
1 Answer
0
In database management systems, indexes play a vital role in optimizing data retrieval operations. Two common types of indexes used in relational databases are clustered indexes and non-clustered indexes. Both types serve different purposes and have distinct characteristics that affect database performance.
A clustered index determines the physical order of data rows in a table. It defines the arrangement of the table's data based on the values of one or more columns. In other words, a clustered index determines the storage order of the data on disk. Each table can have only one clustered index, as it directly affects the physical layout of the data.
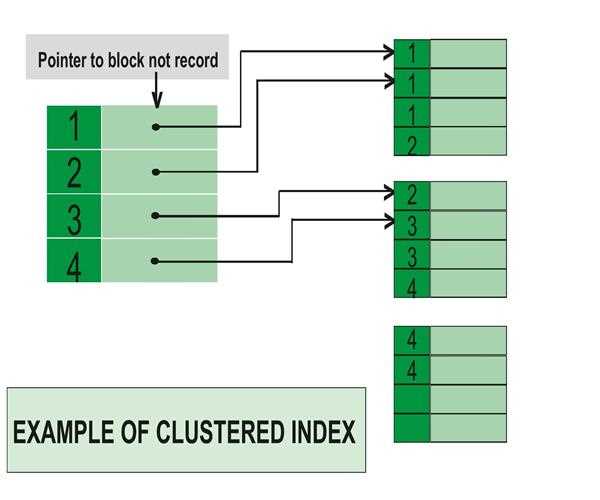
On the other hand, a non-clustered index is a separate structure that stores a copy of selected columns from a table along with a reference to the corresponding rows. It is created on a specific column or set of columns to improve the retrieval speed of data based on those columns. Unlike clustered indexes, multiple non-clustered indexes can be created on a single table.
The primary difference between clustered and non-clustered indexes lies in their impact on the physical order of data and the search operations they optimize. Let's delve deeper into the characteristics of each type:
Physical Order: A clustered index determines the physical order of the data rows. It rearranges the data in the table to match the index's sorting order. In contrast, a non-clustered index does not affect the physical order of data but provides an additional structure for efficient data retrieval.
Data Storage: With a clustered index, data rows are stored in the same order as the index. This means that adding, deleting, or updating data may require physical reordering of the rows, which can be time-consuming for large tables. In contrast, non-clustered indexes store a copy of the indexed columns separately from the table data, resulting in faster data modification operations.
Search Performance: A clustered index excels in optimizing queries that involve range scans or queries that return a large number of consecutive rows. Since the data rows are physically stored in the index order, the search operations can directly traverse the index structure to locate the desired data. Non-clustered indexes, on the other hand, are efficient for searching specific values or performing equality checks on the indexed columns.
Index Size: Clustered indexes tend to be larger in size compared to non-clustered indexes because they store the entire data row in the index. Non-clustered indexes only store a copy of the indexed columns along with row references, resulting in a smaller index size.
Index Usage: Due to their impact on the physical data order, clustered indexes are commonly used on columns that are frequently used for sorting or range-based queries. Non-clustered indexes, on the other hand, are more versatile and can be created on various columns based on different query requirements.
In summary, the key distinction between clustered and non-clustered indexes lies in their impact on the physical data order, storage approach, search performance, and index size. Clustered indexes determine the physical order of data rows, optimizing range scans and large result sets, while non-clustered indexes provide additional structures for efficient searching based on specific columns. Understanding these differences is crucial for effectively utilizing indexes and improving database performance.