1
What is Normalization?
What is Normalization?
Normalization!

It is a process through which the data is been arranged in a table resulting in the intended and unambiguous data. These type of normalization is intrinsic to the theory of relational database. This may cause data duplication within the database thus, resulting the birth of tables in addition to previous.
An IBM researcher E.F. Codd, in 1970 traced the concept of database normalization via publishing a paper briefing about the Model of Relational Database. One of the essential elements of a relational database was described by Codd as “An N-Form for database relations”. It clutched all the attention of the audience in the period 1970-1980 where the data storage was very necessary via efficient means while the disk drives were expensive. Since that period techniques like Denormalization also taken up the floor.
While these rules may lead to the data duplication, it prevents unnecessary duplication or redundant data. Database Normalization is a clarified process, initiate post the exercise of data identification present in the relational database, defining tables along with the column post relationships identification.
Let us consider an example, consider a table which is tracking a record of the price of a commodity while deleting the customer entry in the table will land up deleting the price of the commodity too. Thus, normalizing the data would mean to consider the answer to the query by separating the above table into two… Which consist of, the product brought by the customer and customer’s detail and information detailing about the product and its price respectively. Thus, modifying either of the tables would not affect the other one by any means.
The degree of Normalization:
Expanding its meaning further:
First normal form (1NF):
A basic level of normalization. Thus, it is like a dovetail for any database definition:
Second normal form (2NF):
At this level of normalization where one column could not interpret the content of the other column, should be a function of the other column in a table. Considering an example, a table consisting of three columns holding Customer ID, Product Sold and Product Price pre-sold, the Product Price would be the function for both the other columns i.e, Customer ID and the Product.
Third normal form (3NF):
Modification in the 2-NF is possible to still that’s because advancement in one row belonging to a table may influence data related to this information in other tables.
Let us consider a short example, to show about the above mentioned statement, consider a table named ‘Customer’, a row elaborating about a customer’s purchase when removed along with the same it will remove the entries detailing about the product price also whereas, in third normal form the division of the tables would be so that the tracking of product price would be done separately.
Boyce and Codd Normal Form:
It is the superior version of 3-NF. This form encounter with certain sort of oddity that cannot be handled by Third Normal Form. If various overlapping candidate keys are not mentioned in 3-NF, then it is said to be in BCNF.
Following conditions are important for a table, to be in BCN Form:
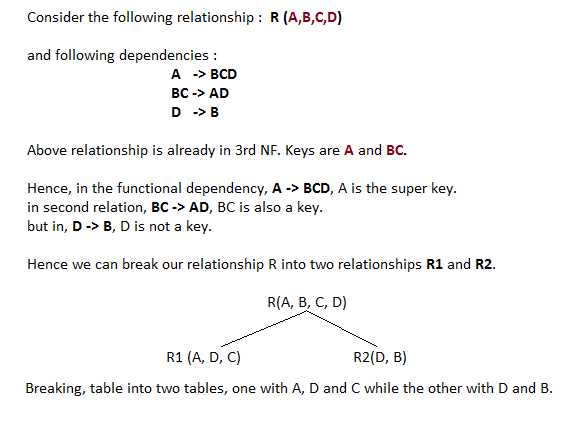
Extensions of simple everyday paperwork include the domain/key regular form, wherein a key uniquely identifies every row in a desk, and the Boyce-Codd normal form, which refines and complements the strategies used inside the 3NF to deal with some styles of anomalies.
Database normalization's capacity to keep away from or reduce facts anomalies, records redundancies and records duplications, at the same time as enhancing facts integrity, have made it an important part of the statistics developer's toolkit for decades. it has been one of the hallmarks of the relational facts model.
The relational version arose in a technology when enterprise statistics have been, first and most important, on paper. its use of tables was, in a few part, an attempt to reflect the kind of tables used on paper that acted as the original illustration of the (in most cases accounting) records. the need to support that kind of representation has waned as digital-first representations of information have changed paper-first information.
But other elements have additionally contributed to hard the dominance of database normalization.
Over time, persisted discounts within the cost of disk storage, as well as new analytical architectures, have reduced to normalization's supremacy. the upward thrust of Denormalization as an opportunity commenced in earnest with the arrival of statistics warehouses, starting in the Nineties. more currently, document-oriented no SQL databases have arisen; these and other nonrelational systems often tap into nondisk-orientated garage kinds. now, more than in the beyond, data architects and builders stability information normalization and Denormalization as they layout their structures.
Attaching a link for more information!
Well, the brief description of Normalization has been covered!!!
Hopefully a better version for your self-explanation!
All The Best!